Fine-tuning LLaVA for Web Agents
Group project at CMU. We took LLaVA-v1.5-7B, fine-tuned it on a web-UI dataset, and pushed the open-model score on VisualWebBench up.
- Action Prediction
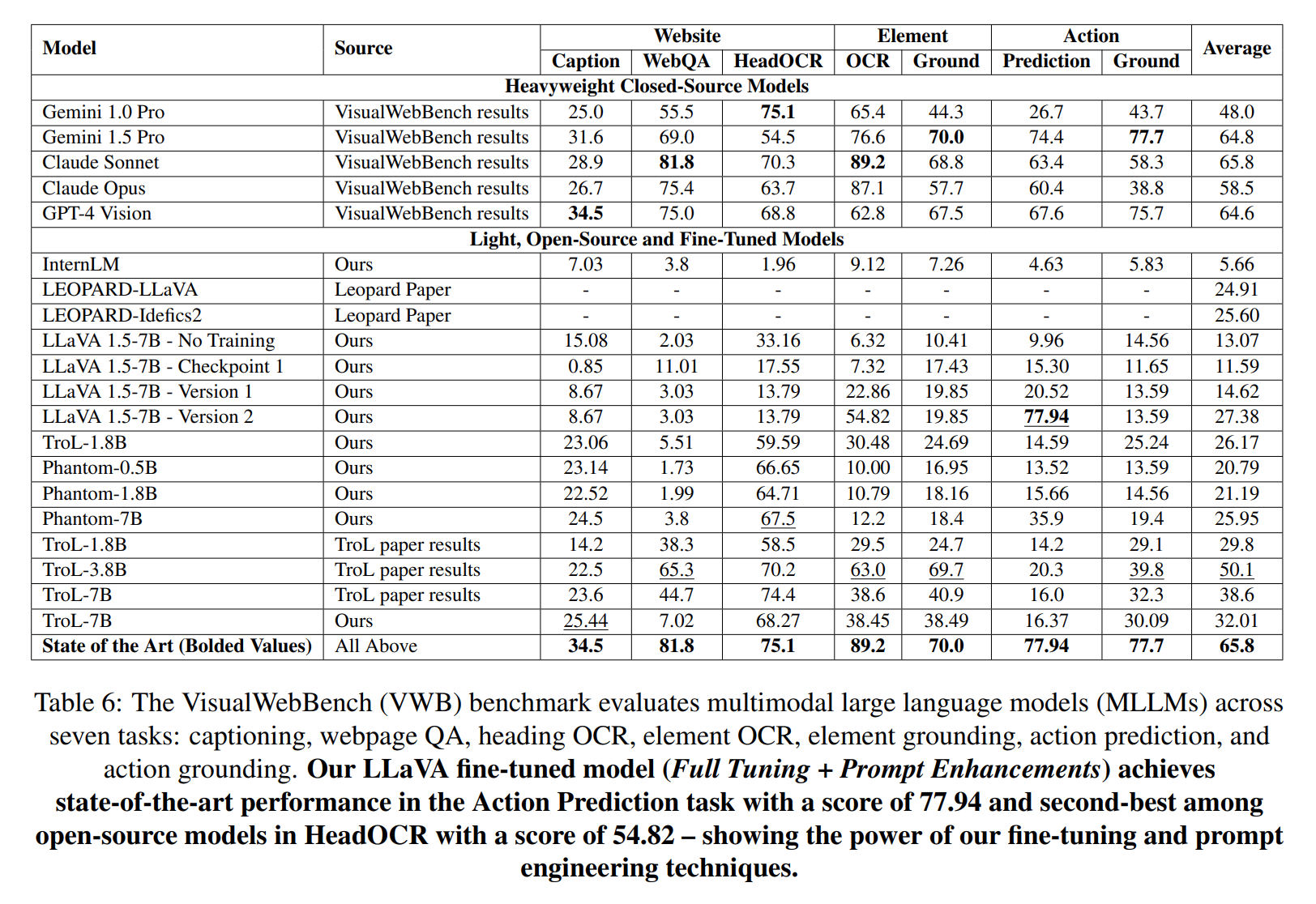
- 77.94%
- Heading OCR
- 54.82%
- Hardware
- 1× A100
Trained on a WebUI dataset for the right reason.
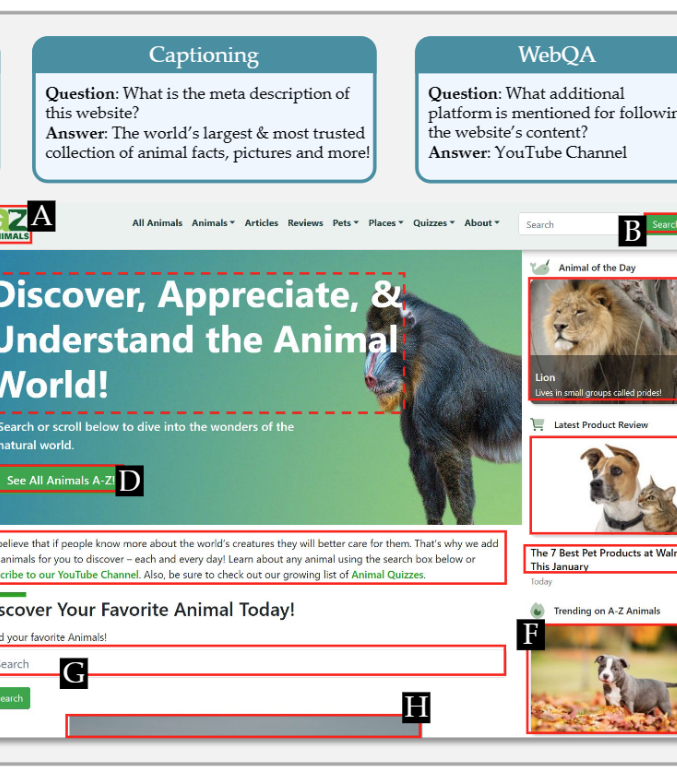
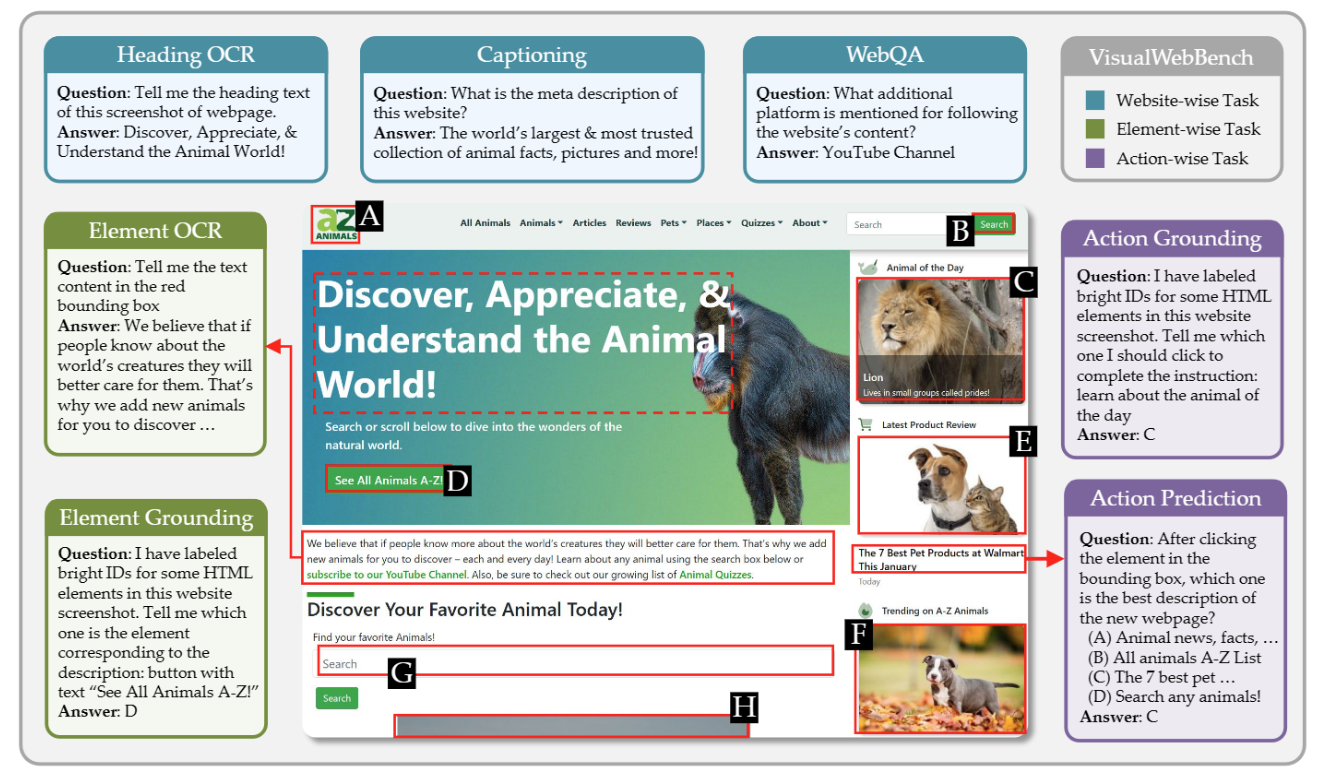
We LoRA-tuned LLaVA-v1.5-7B on MultiUI, a diverse dataset of web-based UI interactions. As far as we could tell at the time, this was the first time a model was trained on WebUI tasks specifically to improve generalizability to VisualWebBench, rather than treating it as just another evaluation target. Conducted detailed visual attention analyses along the way to track alignment between textual and visual modalities.
Task-specific prompt designs and preprocessing did most of the work.
The bigger lever turned out to be the prompt: task-specific designs and preprocessing for OCR, grounding, and captioning moved scores more than several rounds of additional fine-tuning. Bounding-box hints in the prompt mattered more than explicit visual cues in the image.
Best open-source small-model score, briefly.
On VisualWebBench (as of 12/15/2024): 77.94% on Action Prediction, the best result we found at that scale. 54.82% on Heading OCR, the best among open low-parameter models we compared against. Numbers will have moved since, this was a snapshot from the course's final report.
Visual attention helped most where the model was bluffing.
We spent time looking at attention maps to understand alignment between text and image tokens. The maps were noisy in the cases the model got right, and weirdly confident in the cases it got wrong, a familiar pattern for anyone who's run interp tooling. It told us where prompt structure could carry more weight than training data.
MMML capstone at CMU LTI. The project pushed open-source multimodal models by focusing on compact architectures and improving performance on the VisualWebBench benchmark. The starting point was a baseline LLaVA-v1.5-7B checkpoint that did poorly on web-grounded tasks. Most of the work was unglamorous: cleaning and reformatting the MultiUI training data, picking a LoRA configuration that fit on a single A100, and running enough ablations to know which screenshots actually moved the metric. The interesting finding was that explicit visual cues mattered less than expected and bounding-box hints in the prompt mattered more. Done with Akshay Badagabettu, Aayush Shah, and Sai Yarlagadda.
- LLaVA
- LoRA
- PyTorch
- VisualWebBench
- MultiUI